背景
近期工作中做了 LLM 长记忆功能,对此中的思路,技术做下总结。顺便为了练习自己的系统设计能力,这里按照系统设计的方式来整理
什么是长记忆
简单来说就是让大模型具备记忆功能,记住某个人。产品形态上可以是个人助手。不同于某次会话上下文记忆,长记忆具备的特点:
- 跟随个人的:我们目前常见的短期记忆只是跟随某次会话
- 时间长:1年,5年,10年,……,终生
- 个人信息相关的:比如个人爱好,心情变化,健康,工作,生活等这些属于个人记忆。客观信息事实信息比如:美国在北美洲,地球是圆的等这些不需要作为记忆信息。
- 多种类型的:如上条有不同类型的记忆,不同类型的记忆里处理方式有很大差异,比如:日程相关的需要处理时间,绝对时间的转换,个人爱好相关的,比较简单,直接用类似图谱的三元组信息即可,办公工作内容型的记忆类似。
功能点及非功能点梳理
总体其实为了实现个人助手的产品功能。这个助手在产品形态上是一个普通对话机器人,系统的具备的功能及非功能点需求大致如下:
功能点
- 登录,因为是私人助手嘛,得知道用户是谁。
- 对话:这个不用说了,是助手的主题功能
- 配置功能,因为记忆有很多种类型,在助手里最好有配置,比如我想主要是工作,那日程安排比较重要,生活。如果多有记忆都要配置,那就是一个超级个人助手
- 记忆生产:根据配置信息,做不同类型的记忆提取存储
- 记忆消费:是指根据记忆:做下健康管理,饮食管理,工作学习计划,日程计划,等等。
非功能点
- 短期能同时处理 1w+ 人数的并发,长期的话人数可能扩充到 10W+,甚至更多。每天可能有 50W 的请求
- 响应时间:在记忆消费时能做到 3s - 5s 内有响应,3s-30s 内响应完成。
- 数据规模,根据每个人的配置,记忆长短不同,数据规模有不同要求
方案
工作流程图
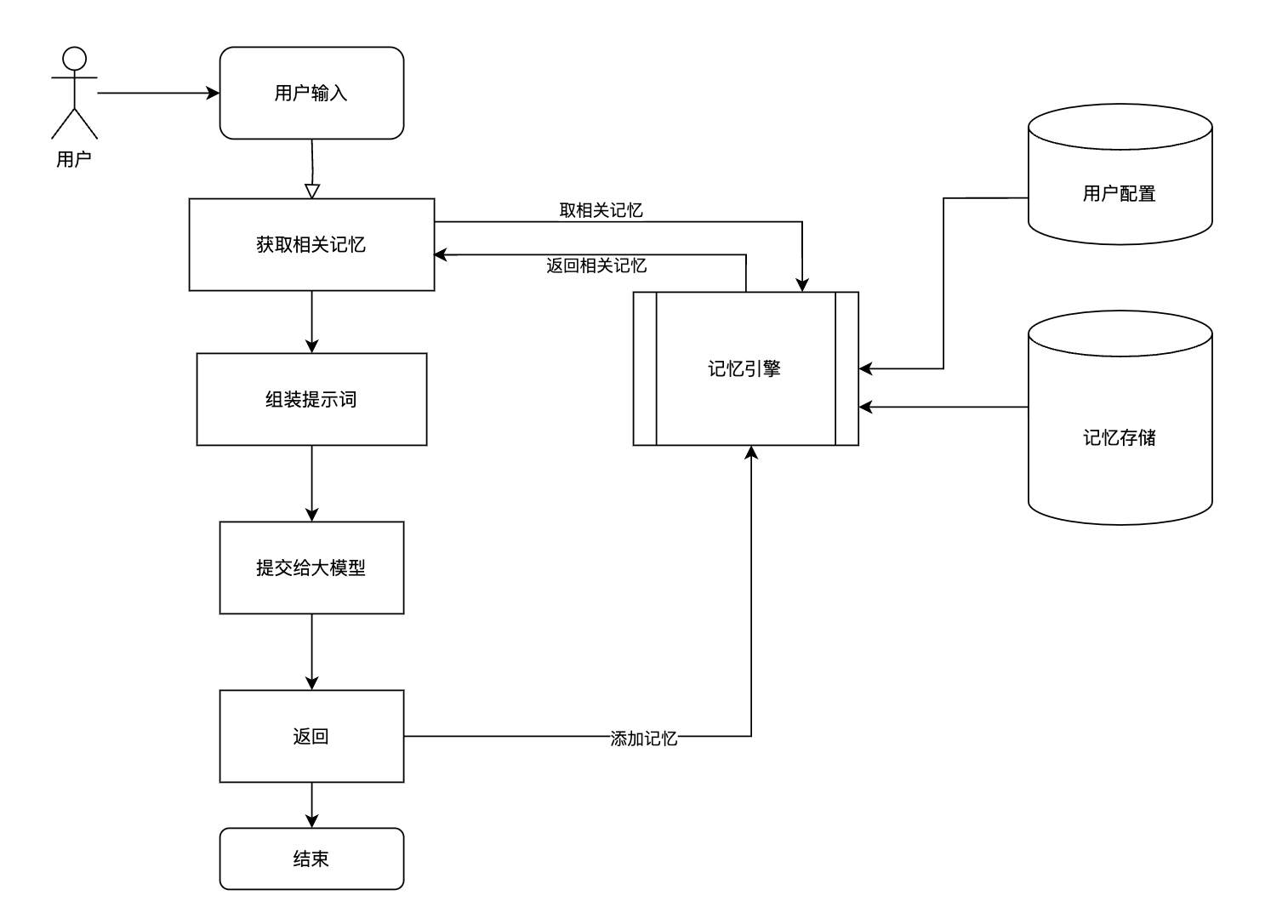
如图所示。总体为一个 RAG 流程,其中核心是记忆引擎的部分。由于rag流程基础的东西,在社区里做的比较多,也比较简单,不做过多强调。核心强调记忆引擎的东西。
记忆引擎
记忆引擎里完成的功能:
- 记忆生产 根据配置信息生产一些垂类记忆
- 记忆存储 把记忆抽出来后
- 记忆消费 根据用户的问题,召回相关的记忆,并做简单推理规划
记忆生产
这里输入是会话信息,需要做的是从会话信息里提取记忆实体。主要涉及到自然语言处理的部分。 知识图谱,我们使用知识图谱来完成记忆的载体。
知识图谱的实体抽取,以及图数据库语法都是用额外的大模型来推理完成
提示词设计
// 信息抽取
`
你是一个信息提取专家
用户的输入如下:{query}
实体信息:
`
// 记忆更新
`
你是一个图数据专家,请生成neo4j的sql语句
历史记忆如下:{memories}
新的记忆如下:{memory}
sql:
`
这里只给出部分,因为其他一些垂类的内容。其他还有很多,也算是核心。
记忆消费
这里就是拼装提示词,召回后相关信息,做一下记忆拼接,最终的提示词
大概如下
`历史记忆如下: {memories}
问题: {query}
`
把记忆引擎抽离出来一个独立服务
这个记忆引擎可以抽你出来一个独立服务,给其他提供服务。
未来如果有类人机器人出现,这个引擎可以作为其大脑的一部分。
小节
本质上记忆引擎里的核心还是提示词,属于是:用大模型本身去解决大模型的问题。是不是有点类似于:我不是要你的钱,我只是拿你的钱办你的事。和珅表示这事我熟悉
技术选型
后端:Python FastApi 存储:图数据库,向量数据库,Postgresql 前端:React Nextjs
未来规划
交互上更加拟人一些,比如加入 tts,以及 stt
社区方案
我在实践过程中严重依赖了这个方案,不得不说社区力量还是强大
总结
在实际中体验下来,最终方案已经基本能用。提交给产品后,收获到了一些正向反馈。目前这个产品可以定位为超级个人助理。可以配置记忆倾向点,也可以手动录入一些记忆信息,以及一些非结构化的记忆。
方案思路很简单,调优巨复杂。做过的估计都有体会,这也是现阶段很多AI应用的通用问题。所以会涌现出很多奇淫巧技让这些效果变好,或许这就是技术存在的意义吧:在有限的条件下尽量产生价值
方案上还是会演进的,因为目前总体上还是提示词工程的玩法。这种模式会受到大模型本身技术发展影响的。大模型的窗口,推理精读都会影响我们的方案设计。
Any Way 无论如何。在 AI 时代下,此类产品会越来越多,我们一定要利用好这些产品来辅助提升我们的效率。让我们自己变成超级个体,一个人相当于一个团队。